Kuala Lumpur, Malaysia — 16 APRIL 2026
Scicom Advances Open-Source AI Leadership with Launch of Two Flagship Developer Tools and a GPU Calculator
The company's AI Enterprise division releases pyremote, llm-benchmaq, and a GPU Calculator — purpose-built tools that simplify AI infrastructure management, standardize large language model benchmarking, and give any organization the ability to estimate GPU requirements and project real-world inference performance.
The Lead
Scicom (MSC) Berhad announces the public release of two open-source tools and a live inference planning tool developed by its AI Enterprise Solutions team: pyremote, llm-benchmaq, and the AIES GPU Calculator. Together, these releases mark a significant step in Scicom's commitment to building accessible, enterprise-grade AI infrastructure — empowering organizations to deploy, evaluate, and right-size artificial intelligence solutions with greater speed, consistency, and confidence. The open-source tools are publicly available via Scicom's official GitHub repository, and the GPU Calculator is accessible now at gpu-calculator.aies.scicom.dev.
The Strategy
As demand for large language model (LLM) integration accelerates across industries, organizations face a growing challenge: managing the complexity of AI deployments while ensuring consistent, measurable performance. Scicom's AI Enterprise division designed pyremote and llm-benchmaq to address precisely these friction points, reducing the operational burden on engineering teams and introducing a structured, repeatable framework for AI performance measurement.
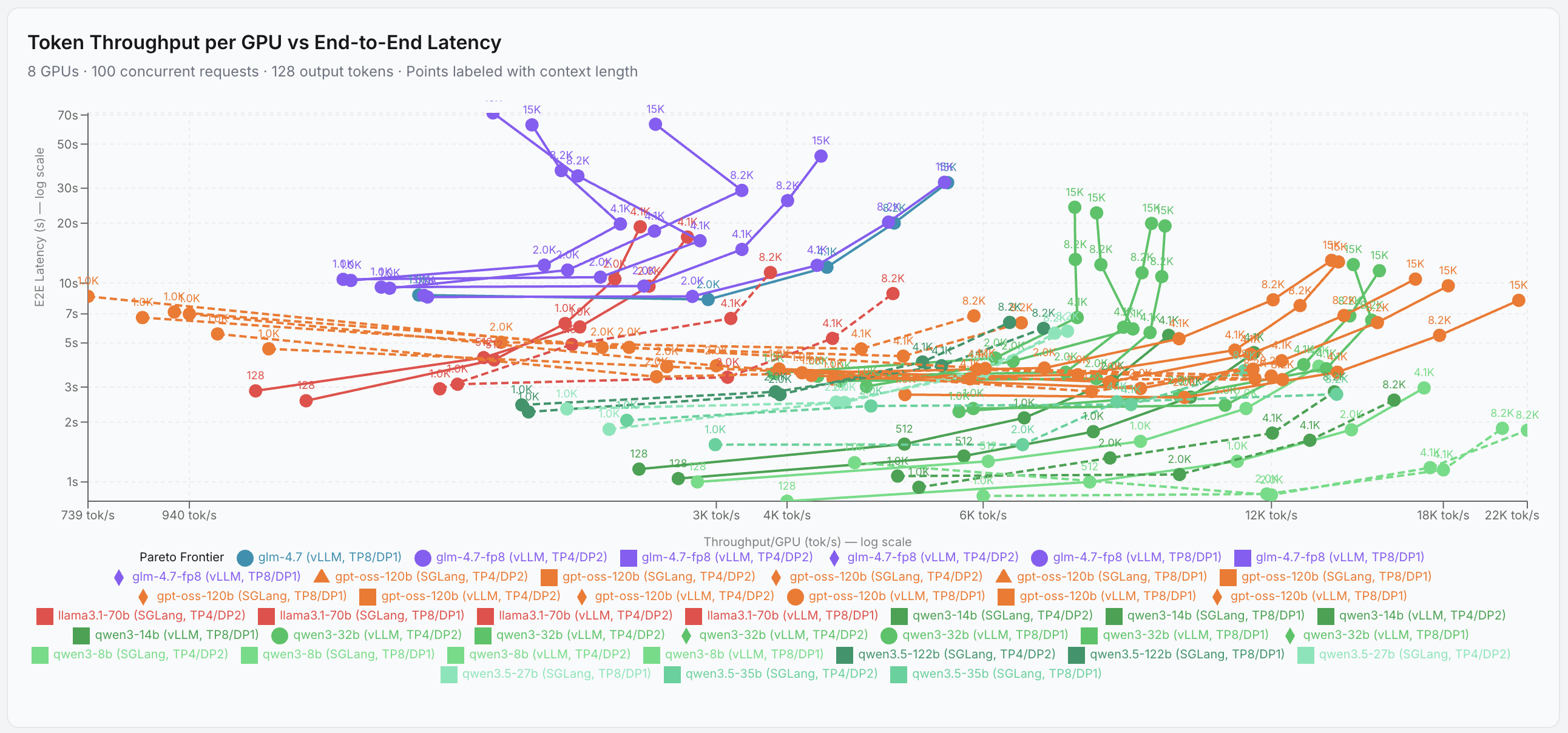
That benchmarking work was not merely theoretical. The team conducted more than 250 individual benchmark runs spanning dense and mixture-of-experts (MoE) model architectures, multiple context lengths, and varying concurrency levels. The resulting dataset captures real-world inference behavior across a broad configuration space — and it directly powers a new public tool: the AIES GPU Calculator. Given a target model, context length, and throughput requirement, the calculator estimates the number of GPUs needed and projects key inference metrics — including time to first token (TTFT), output throughput, and end-to-end latency — through both interpolation and extrapolation across the benchmark dataset. For teams planning deployments or evaluating infrastructure spend, this closes the gap between raw benchmark data and actionable procurement decisions.
These releases are particularly timely as the industry navigates a generational hardware transition. With Blackwell-generation GPUs delivering up to 2.5× faster training and significantly lower cost-per-token compared to previous-generation Hopper systems, organizations must now evaluate their infrastructure economics with greater precision. The GPU Calculator was built precisely for this moment: giving teams a data-grounded way to compare configurations before committing capital.
These releases are consistent with Scicom's broader strategic direction in digital transformation and AI-enhanced service delivery. By contributing production-ready tooling to the open-source community and publishing a freely accessible GPU planning tool, Scicom reinforces its position not only as a technology adopter, but as an active architect of the evolving AI ecosystem — one that serves enterprise clients across government, telecommunications, and financial services sectors.
Executive Voice
“We are committed to keeping our AI infrastructure tools open-source — not just because it's the right approach for the community, but because we want the world to see what we're building. These tools solve real problems we've encountered in production, and we believe they can help other organizations accelerate their AI journey. We encourage developers and enterprises everywhere to use them, build on them, and make them even better.”
“In today's GPU economy, inference costs have dropped dramatically — but only for organizations that can measure and optimize their deployments effectively. llm-benchmaq gives teams the visibility they need to make informed infrastructure decisions, whether they're comparing Hopper versus Blackwell performance or evaluating cost-per-token across different model configurations. And with more than 250 benchmarks now underpinning the GPU Calculator, we can go further: teams can arrive with a target workload and leave with a concrete GPU estimate and projected inference metrics — before writing a single line of deployment code.”
Key Highlights
pyremote — Simplified Remote AI Execution
pyremote enables engineering teams to run code on remote servers, including high-performance GPU infrastructure such as NVIDIA H100, H200, and B200 systems, as seamlessly as if it were running on a local machine. This dramatically reduces setup complexity for distributed AI workloads, allowing teams to focus on building rather than managing infrastructure.
llm-benchmaq — Standardized LLM Performance Evaluation
llm-benchmaq provides a ready-to-use benchmarking framework that allows organizations to consistently measure and compare the performance of large language models across different hardware configurations. The tool delivers a clear, replicable methodology for evaluating AI models — a critical capability for enterprises conducting procurement, quality assurance, or compliance assessments. Scicom's own team used llm-benchmaq to run more than 250 benchmarks spanning dense and MoE model architectures, multiple context lengths, and varying concurrency levels, generating the dataset that now powers the AIES GPU Calculator.
AIES GPU Calculator — From Benchmark Data to Deployment Decisions
The direct output of Scicom's benchmarking program, the AIES GPU Calculator translates raw performance data into actionable infrastructure estimates. Users specify a target model, context length, and concurrency profile; the calculator returns the estimated number of GPUs required along with projected inference metrics — time to first token (TTFT), output throughput, and end-to-end latency. Estimates are derived through interpolation and extrapolation across the full benchmark dataset, covering both dense and mixture-of-experts model families. The tool is freely accessible at gpu-calculator.aies.scicom.dev.
Open-Source Commitment & Community Access
Both tools are openly published under Scicom's AI Enterprise GitHub organization, making them freely accessible to developers, enterprises, and research institutions worldwide. This marks a continued expansion of Scicom's open-source portfolio, which now includes multilingual text-to-speech datasets and large-scale agentic training datasets. The GPU Calculator, built on top of this open benchmarking foundation, is available as a live web tool — no installation required.
About Scicom (MSC) Berhad
Scicom (MSC) Berhad is a leading global digital transformation solutions provider. Listed on the Main Market of Bursa Malaysia, Scicom specializes in integrated customer lifecycle management, digital government services, and e-commerce solutions. With a footprint spanning multiple continents, Scicom delivers innovative, AI-enhanced services to a diverse portfolio of Fortune 500 companies and government agencies. For further information, visit scicom.com.my.
This press release contains forward-looking statements that involve risks and uncertainties. Actual results may differ materially from those anticipated. Scicom (MSC) Berhad is listed on the Main Market of Bursa Malaysia Securities Berhad.